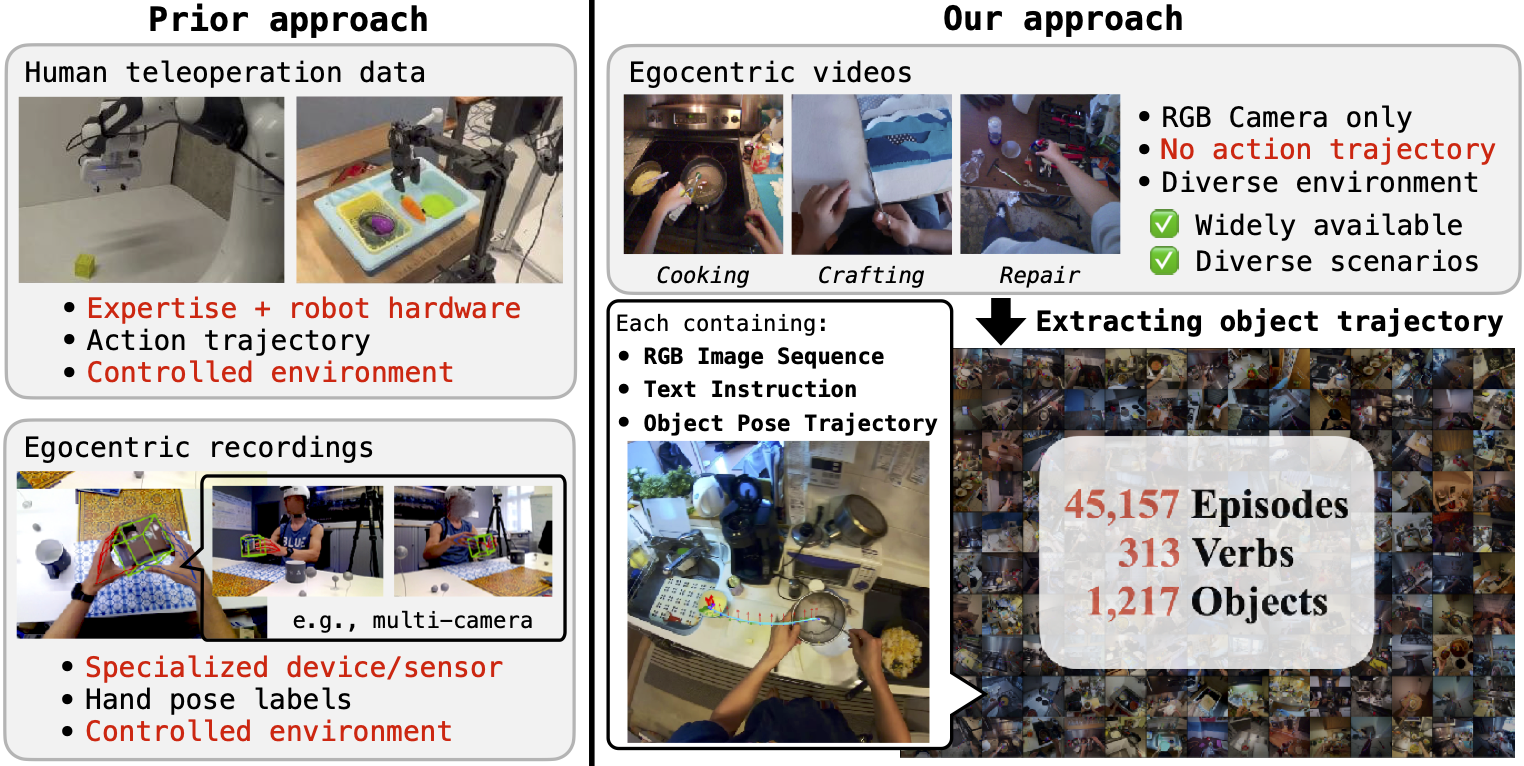
Egocentric videos capture how humans manipulate objects and tools, providing diverse motion cues for learning object manipulation. Unlike the costly, expert-driven manual teleoperation commonly used in training Vision-Language-Action models (VLAs), egocentric videos offer a scalable alternative. However, prior studies that leverage such videos for training robot policies typically rely on auxiliary annotations, such as detailed hand-pose recordings. Consequently, it remains unclear whether VLAs can be trained directly from raw egocentric videos. In this work, we address this challenge by leveraging EgoScaler, a framework that extracts 6DoF object manipulation trajectories from egocentric videos without requiring auxiliary recordings. We apply EgoScaler to four large-scale egocentric video datasets and automatically refine noisy or incomplete trajectories, thereby constructing a new large-scale dataset for VLA pre-training. Our experiments with a state-of-the-art π0 architecture in both simulated and real-robot environments yield three key findings: (i) pre-training on our dataset improves task success rates by over 20% compared to training from scratch, (ii) the performance is competitive with that achieved using real-robot datasets, and (iii) combining our dataset with real-robot data yields further improvements. These results demonstrate that egocentric videos constitute a promising and scalable resource for advancing VLA research.
@article{yoshida2025developing,
title={Developing vision-language-action model from egocentric videos},
author={Yoshida, Tomoya and Kurita, Shuhei and Nishimura, Taichi and Mori, Shinsuke},
journal={arXiv preprint arXiv:2509.21986},
year={2025}
}